Обнаружение пикового сигнала в реальном времени
143 Jean-Paul [2014-03-22 23:48:00]
Обновление: Самый эффективный алгоритм до сих пор - это.
В этом вопросе рассматриваются надежные алгоритмы обнаружения внезапных пиков в данных времени в реальном времени.
Рассмотрим следующий набор данных:
p = [1 1 1.1 1 0.9 1 1 1.1 1 0.9 1 1.1 1 1 0.9 1 1 1.1 1 1 1 1 1.1 0.9 1 1.1 1 1 0.9 1, ...
1.1 1 1 1.1 1 0.8 0.9 1 1.2 0.9 1 1 1.1 1.2 1 1.5 1 3 2 5 3 2 1 1 1 0.9 1 1 3, ...
2.6 4 3 3.2 2 1 1 0.8 4 4 2 2.5 1 1 1];
(формат Matlab, но это не язык, а алгоритм)
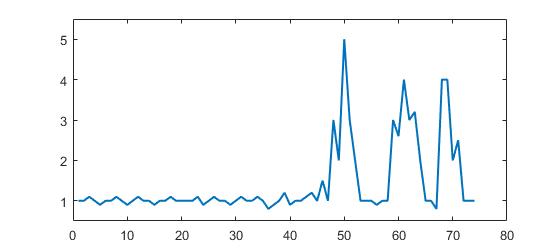
Вы можете четко видеть, что есть три больших пика и небольшие пики. Этот набор данных является конкретным примером класса наборов данных таймсеров, о которых идет речь. Этот класс наборов данных имеет две общие особенности:
- Существует основной шум с общим значением
- Существуют большие "пики" или "более высокие точки данных", которые значительно отклоняются от шума.
Предположим также, что:
- ширина пиков не может быть определена заранее
- высота пиков явно отличается от других значений
- используемый алгоритм должен вычислять реальное время (поэтому измените с каждым новым datapoint)
Для такой ситуации необходимо построить граничное значение, которое вызывает сигналы. Однако граничное значение не может быть статическим и должно определяться в реальном времени на основе алгоритма.
Мой вопрос: что такое хороший алгоритм для вычисления таких пороговых значений в реальном времени? Существуют ли конкретные алгоритмы для таких ситуаций? Каковы наиболее известные алгоритмы?
Надежные алгоритмы или полезные идеи все очень ценятся. (может отвечать на любом языке: об алгоритме)
language-agnostic algorithm time-series signal-processing data-analysis
25 ответов
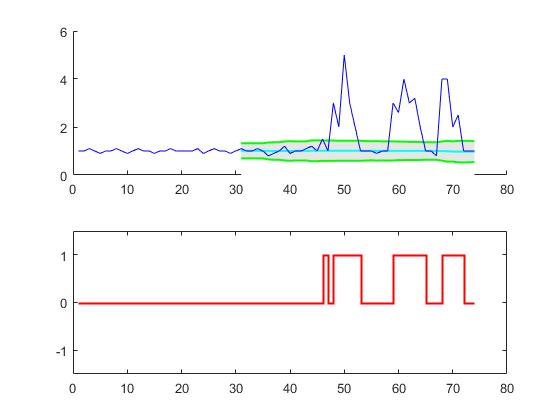
192 Решение Jean-Paul [2014-03-25 19:16:00]
Сглаженный алгоритм z-показателя (обнаружение пика с устойчивым порогом)
Я построил алгоритм, который очень хорошо работает для этих типов наборов данных. Он основан на принципе дисперсии: если новая точка данных представляет собой заданное число х стандартных отклонений от некоторого скользящего среднего, алгоритм подает сигнал (также называемый z-счетом). Алгоритм очень надежен, потому что он строит отдельное скользящее среднее и отклонение, так что сигналы не нарушают порог. Поэтому будущие сигналы идентифицируются примерно с одинаковой точностью, независимо от количества предыдущих сигналов. Алгоритм принимает 3 входа: lag = the lag of the moving window, threshold = the z-score at which the algorithm signals и influence = the influence (between 0 and 1) of new signals on the mean and standard deviation. Например, lag в 5 будет использовать последние 5 наблюдений для сглаживания данных. threshold 3,5 будет сигнализировать, если точка данных находится в 3,5 стандартных отклонениях от скользящего среднего. И influence 0,5 дает сигналы половину влияния, которое имеют нормальные точки данных. Аналогично, influence 0 полностью игнорирует сигналы для пересчета нового порога. Поэтому влияние 0 является наиболее надежным вариантом (но предполагает стационарность); установка варианта влияния на 1 наименее устойчива. Поэтому для нестационарных данных параметр влияния должен находиться где-то между 0 и 1.
Это работает следующим образом:
ПСЕВДОКОД
# Let y be a vector of timeseries data of at least length lag+2
# Let mean() be a function that calculates the mean
# Let std() be a function that calculates the standard deviaton
# Let absolute() be the absolute value function
# Settings (the ones below are examples: choose what is best for your data)
set lag to 5; # lag 5 for the smoothing functions
set threshold to 3.5; # 3.5 standard deviations for signal
set influence to 0.5; # between 0 and 1, where 1 is normal influence, 0.5 is half
# Initialise variables
set signals to vector 0,...,0 of length of y; # Initialise signal results
set filteredY to y(1),...,y(lag) # Initialise filtered series
set avgFilter to null; # Initialise average filter
set stdFilter to null; # Initialise std. filter
set avgFilter(lag) to mean(y(1),...,y(lag)); # Initialise first value
set stdFilter(lag) to std(y(1),...,y(lag)); # Initialise first value
for i=lag+1,...,t do
if absolute(y(i) - avgFilter(i-1)) > threshold*stdFilter(i-1) then
if y(i) > avgFilter(i-1) then
set signals(i) to +1; # Positive signal
else
set signals(i) to -1; # Negative signal
end
# Make influence lower
set filteredY(i) to influence*y(i) + (1-influence)*filteredY(i-1);
else
set signals(i) to 0; # No signal
set filteredY(i) to y(i);
end
# Adjust the filters
set avgFilter(i) to mean(filteredY(i-lag),...,filteredY(i));
set stdFilter(i) to std(filteredY(i-lag),...,filteredY(i));
end
Эмпирические правила для выбора хороших параметров для ваших данных можно найти ниже.
демонстрация

Код Matlab для этой демонстрации можно найти здесь.Чтобы использовать демо, просто запустите его и создайте временной ряд самостоятельно, нажав на верхнюю диаграмму.Алгоритм начинает работать после вывода lag числа наблюдений.
Результат
Для исходного вопроса этот алгоритм даст следующий вывод:
Реализации на разных языках программирования:
-
Матлаб (я)
-
R (я)
-
Golang (Xeoncross)
-
Питон (Р. Киселев)
-
Свифт (я)
-
Groovy (JoshuaCWebDeveloper)
-
C++ (бред)
-
C++ (Анимеш Пандей)
-
Ржавчина
-
Scala (Майк Робертс)
-
Котлин (леодерпрофи)
-
Руби (Киммо Лехто)
-
Фортран [для обнаружения резонанса] (THo)
-
Джулия (Мэтт Кэмп)
-
С# (Ocean Airdrop)
-
C (DavidC)
Практические рекомендации по настройке алгоритма
lag: параметр lag определяет, насколько ваши данные будут сглажены и насколько адаптивен алгоритм к изменениям долгосрочного среднего значения данных. Чем более постоянны ваши данные, тем больше задержек вы должны включить (это должно повысить надежность алгоритма). Если ваши данные содержат изменяющиеся во времени тренды, вы должны подумать о том, как быстро вы хотите, чтобы алгоритм адаптировался к этим тенденциям. Т.е., если вы установите lag в 10, потребуется 10 "периодов", прежде чем порог алгоритма будет скорректирован на любые систематические изменения в долгосрочной средней. Так что выбирайте параметр lag на основе трендового поведения ваших данных и того, насколько адаптивным вы хотите, чтобы алгоритм был.
influence: этот параметр определяет влияние сигналов на порог обнаружения алгоритма. Если задано значение 0, сигналы не влияют на порог, так что будущие сигналы обнаруживаются на основе порога, который рассчитывается со средним и стандартным отклонением, на которое не влияют предыдущие сигналы. Еще один способ думать об этом заключается в том, что если вы установите влияние на 0, вы неявно предполагаете стационарность (т.е. независимо от того, сколько существует сигналов, временной ряд всегда возвращается к одному и тому же среднему значению в долгосрочной перспективе). Если это не так, вы должны поместить параметр влияния где-то между 0 и 1, в зависимости от степени, в которой сигналы могут систематически влиять на изменяющийся во времени тренд данных. Например, если сигналы приводят к структурному разрыву долгосрочного среднего значения временного ряда, параметр влияния должен быть высоким (близким к 1), чтобы порог мог быстро адаптироваться к этим изменениям.
threshold: пороговый параметр - это число стандартных отклонений от скользящего среднего, выше которого алгоритм будет классифицировать новый пункт данных как сигнал. Например, если новая точка данных на 4,0 стандартных отклонения выше скользящего среднего, а пороговый параметр установлен на 3,5, алгоритм идентифицирует точку данных как сигнал. Этот параметр должен быть установлен исходя из ожидаемого количества сигналов. Например, если ваши данные нормально распределены, пороговое значение (или: z-оценка), равное 3,5, соответствует вероятности сигнализации 0,00047 (из этой таблицы), что означает, что вы ожидаете сигнал один раз каждые 2128 точек данных (1/0,00047), Таким образом, пороговое значение напрямую влияет на то, насколько чувствителен алгоритм и, следовательно, также на частоту сигналов алгоритма. Изучите свои собственные данные и определите разумный порог, который подает сигнал алгоритму, когда вы этого хотите (здесь могут потребоваться пробные и ошибочные методы, чтобы получить хороший порог для ваших целей).
ВНИМАНИЕ: Приведенный выше код всегда перебирает все точки данных при каждом запуске. При реализации этого кода обязательно разбивайте вычисление сигнала на отдельную функцию (без цикла). Затем, когда новый DataPoint прибыл, обновить filteredY, avgFilter и stdFilter один раз. Не пересчитывайте сигналы для всех данных каждый раз, когда появляется новый пункт данных (как в примере выше), который будет крайне неэффективным и медленным!
Другие способы изменить алгоритм (для потенциальных улучшений):
- Используйте среднее вместо среднего
- Используйте надежную меру масштаба, такую как MAD, вместо стандартного отклонения
- Используйте поле сигнализации, чтобы сигнал не переключался слишком часто
- Изменить способ работы параметра влияния
- По-разному относитесь к сигналам вверх и вниз (асимметричная обработка)
- Создайте отдельный параметр
influenceдля среднего и стандартного (как в этом переводе Swift)
(Известные) академические цитаты к этому ответу:
-
Ciocirdel, GD and Varga, M. (2016). Предсказание выборов на основе просмотров страниц Википедии. Проектная документация, Vrije Universiteit Amsterdam.
-
Catalbas, MC, Cegovnik, T., Sodnik, J. and Gulten, A. (2017). Обнаружение усталости водителя на основе саккадических движений глаз, 10-я Международная конференция по электротехнике и электронике (ELECO), с. 913-917.
-
Виллемс, П. (2017). Настроение контролировало аффективную обстановку для пожилых людей, магистерскую диссертацию, Университет Твенте.
-
Scirea, M., Eklund, P., Togelius, J. & Risi, S. (2017). Первобытно-импровизация: на пути коэволюционной музыкальной импровизации. Информатика и электронная инженерия (CEEC), 2017 (стр. 172-177). IEEE.
-
Scirea, M. (2017). Affective Music Generation и его влияние на опыт игрока. Докторская диссертация, IT University of Copenhagen, Digital Design.
-
Ло, О., Бьюкенен, WJ, Гриффитс, П. и Макфарлейн, Р. (2018), Методы измерения расстояния для улучшенного обнаружения угроз изнутри, Сети безопасности и связи, Vol. 2018, ID статьи 5906368.
-
Мур Дж., Гоффин П., Мейер М., Лундриган П., Патвари Н., Свард К. и Визе Дж. (2018). Управление домашней средой с помощью зондирования, аннотирования и визуализации данных о качестве воздуха. Слушания ACM по Интерактивным, Мобильным, Носимым и Вездесущим Технологиям, 2 (3), 128.
Если вы используете эту функцию где-то, пожалуйста, укажите мне или этот ответ. Если у вас есть какие-либо вопросы относительно этого алгоритма, отправьте их в комментариях ниже или свяжитесь со мной в LinkedIn.
25 R Kiselev [2017-04-20 10:26:00]
Вот реализация Python/numpy сглаженного алгоритма z-score (см. Ответ выше). Здесь вы можете найти суть.
#!/usr/bin/env python
# Implementation of algorithm from /questions/23382/peak-signal-detection-in-realtime-timeseries-data/173212#173212
import numpy as np
import pylab
def thresholding_algo(y, lag, threshold, influence):
signals = np.zeros(len(y))
filteredY = np.array(y)
avgFilter = [0]*len(y)
stdFilter = [0]*len(y)
avgFilter[lag - 1] = np.mean(y[0:lag])
stdFilter[lag - 1] = np.std(y[0:lag])
for i in range(lag, len(y)):
if abs(y[i] - avgFilter[i-1]) > threshold * stdFilter [i-1]:
if y[i] > avgFilter[i-1]:
signals[i] = 1
else:
signals[i] = -1
filteredY[i] = influence * y[i] + (1 - influence) * filteredY[i-1]
avgFilter[i] = np.mean(filteredY[(i-lag+1):i+1])
stdFilter[i] = np.std(filteredY[(i-lag+1):i+1])
else:
signals[i] = 0
filteredY[i] = y[i]
avgFilter[i] = np.mean(filteredY[(i-lag+1):i+1])
stdFilter[i] = np.std(filteredY[(i-lag+1):i+1])
return dict(signals = np.asarray(signals),
avgFilter = np.asarray(avgFilter),
stdFilter = np.asarray(stdFilter))
Ниже приведен тест на том же наборе данных, который дает тот же график, что и в исходном ответе R/Matlab
# Data
y = np.array([1,1,1.1,1,0.9,1,1,1.1,1,0.9,1,1.1,1,1,0.9,1,1,1.1,1,1,1,1,1.1,0.9,1,1.1,1,1,0.9,
1,1.1,1,1,1.1,1,0.8,0.9,1,1.2,0.9,1,1,1.1,1.2,1,1.5,1,3,2,5,3,2,1,1,1,0.9,1,1,3,
2.6,4,3,3.2,2,1,1,0.8,4,4,2,2.5,1,1,1])
# Settings: lag = 30, threshold = 5, influence = 0
lag = 30
threshold = 5
influence = 0
# Run algo with settings from above
result = thresholding_algo(y, lag=lag, threshold=threshold, influence=influence)
# Plot result
pylab.subplot(211)
pylab.plot(np.arange(1, len(y)+1), y)
pylab.plot(np.arange(1, len(y)+1),
result["avgFilter"], color="cyan", lw=2)
pylab.plot(np.arange(1, len(y)+1),
result["avgFilter"] + threshold * result["stdFilter"], color="green", lw=2)
pylab.plot(np.arange(1, len(y)+1),
result["avgFilter"] - threshold * result["stdFilter"], color="green", lw=2)
pylab.subplot(212)
pylab.step(np.arange(1, len(y)+1), result["signals"], color="red", lw=2)
pylab.ylim(-1.5, 1.5)
22 aha [2014-03-23 00:23:00]
Один из подходов заключается в обнаружении пиков на основе следующего наблюдения:
- Время t является пиком, если (y (t) > y (t-1)) && (y (t) > y (t + 1))
Он избегает ложных срабатываний, ожидая окончания восходящего тренда. Это не совсем "реальное время" в том смысле, что он пропустит пик на один дт. чувствительность можно контролировать, требуя разницы для сравнения. Существует компромисс между зашумленным обнаружением и задержкой времени обнаружения. Вы можете обогатить модель, добавив дополнительные параметры:
- пик, если (y (t) - y (t-dt) > m) && (y (t) - y (t + dt) > m)
где dt и m являются параметрами для управления чувствительностью и задержкой времени
Это то, что вы получаете с указанным алгоритмом:
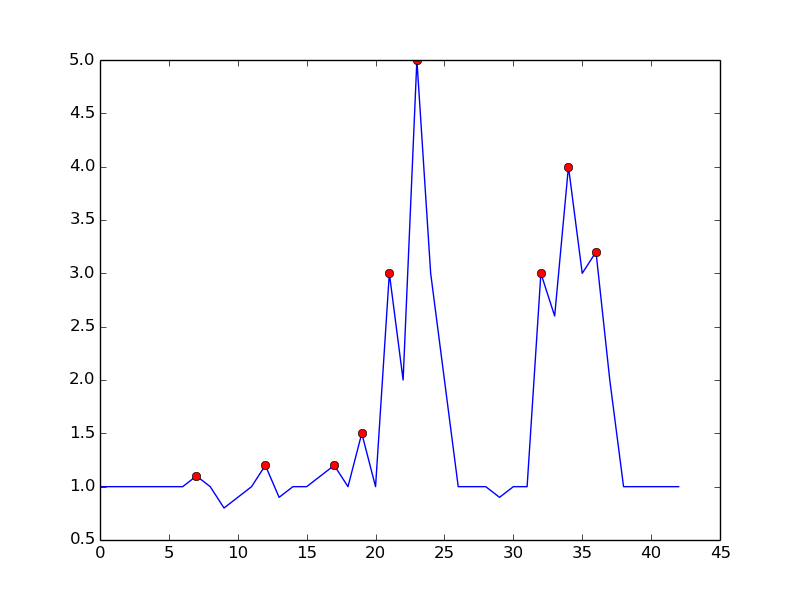
вот код для воспроизведения сюжета в python:
import numpy as np
import matplotlib.pyplot as plt
input = np.array([ 1. , 1. , 1. , 1. , 1. , 1. , 1. , 1.1, 1. , 0.8, 0.9,
1. , 1.2, 0.9, 1. , 1. , 1.1, 1.2, 1. , 1.5, 1. , 3. ,
2. , 5. , 3. , 2. , 1. , 1. , 1. , 0.9, 1. , 1. , 3. ,
2.6, 4. , 3. , 3.2, 2. , 1. , 1. , 1. , 1. , 1. ])
signal = (input > np.roll(input,1)) & (input > np.roll(input,-1))
plt.plot(input)
plt.plot(signal.nonzero()[0], input[signal], 'ro')
plt.show()
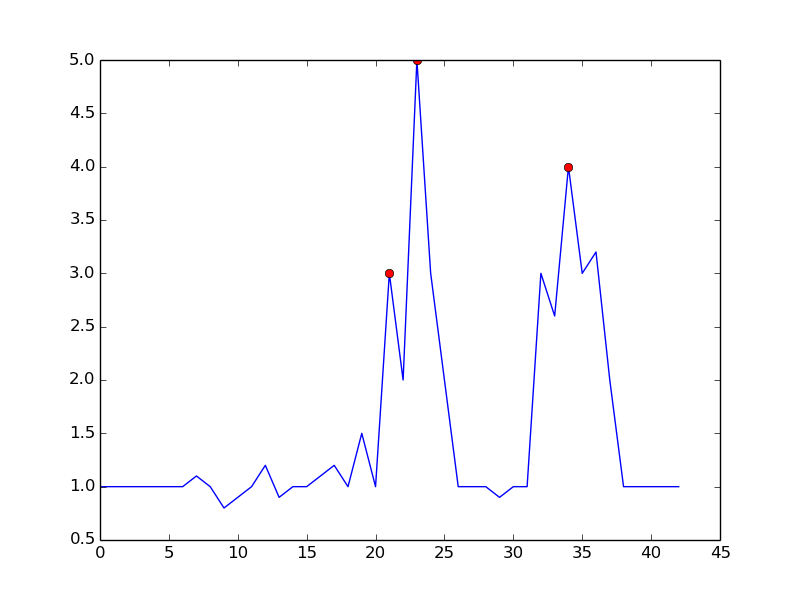
Установив m = 0.5, вы можете получить более чистый сигнал только с одним ложным положительным:
14 cklin [2014-03-31 23:54:00]
В обработке сигналов обнаружение пиков часто выполняется с помощью вейвлет-преобразования. Вы в основном делаете дискретное вейвлет-преобразование в своих данных временных рядов. Нулевые пересечения в возвращаемых подробных коэффициентах будут соответствовать пикам в сигнале временных рядов. Вы получаете разные амплитуды пиков, обнаруженные на разных уровнях коэффициентов детализации, что дает вам многоуровневое разрешение.
9 S. Huber [2017-10-11 08:55:00]
В вычислительной топологии идея персистентной гомологии приводит к быстрому результату, как сортировка чисел - решение. Он не только обнаруживает пики, но и определяет "значимость" пиков естественным образом, что позволяет выбирать пики, которые для вас важны.
Резюме алгоритма. В одномерной установке (временной ряд, вещественный сигнал) алгоритм можно легко описать следующим рисунком:
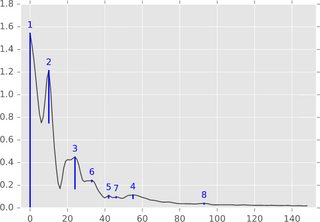
Подумайте о графике функции (или ее наборе подуровня) как о ландшафте и рассмотрите уменьшение уровня воды, начиная с бесконечности уровня (или 1.8 на этом рисунке). Пока уровень уменьшается, на локальных максимумах всплывают острова. На локальных минимумах эти острова сливаются. Одна деталь в этой идее заключается в том, что остров, который появился позже во времени, сливается с более старым островом. "Настойчивость" острова - это время его рождения, минус его время смерти. Длины синих полос показывают стойкость, которая является вышеупомянутым "значением" пика.
Эффективность. Не сложно найти реализацию, которая выполняется в линейном времени - на самом деле это простой, простой цикл - после сортировки значений функций. Таким образом, эта реализация должна быть быстрой на практике и также легко реализована.
Рекомендации. Сводная история и ссылки на мотивацию от стойкой гомологии (поле в вычислительной алгебраической топологии) можно найти здесь: https://www.sthu.org/blog/13-perstopology-peakdetection/index.html
9 jbm [2018-12-12 02:08:00]
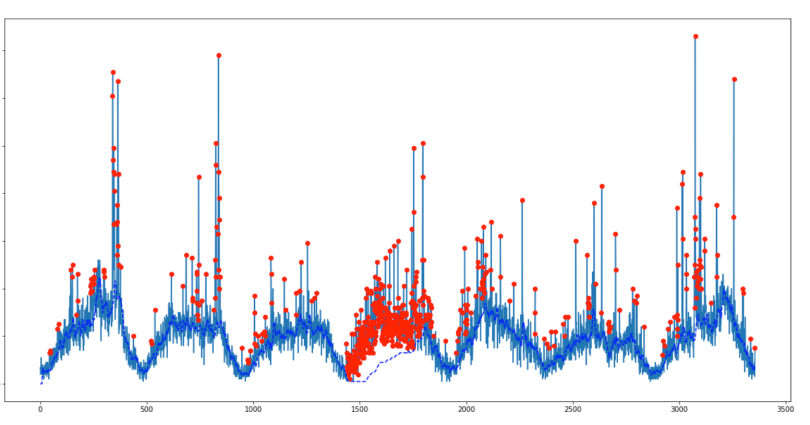
Мы попытались использовать сглаженный алгоритм z-показателя в нашем наборе данных, который приводит к избыточной или недостаточной чувствительности (в зависимости от того, как настроены параметры), с небольшим промежуточным положением. В сигнале трафика на наших сайтах мы наблюдали низкочастотную базовую линию, которая представляет суточный цикл, и даже с наилучшими возможными параметрами (показанными ниже), он все еще затихал, особенно на 4-й день, потому что большинство точек данных были признаны аномальными.
Основываясь на оригинальном алгоритме z-счета, мы нашли способ решить эту проблему с помощью обратной фильтрации. Детали модифицированного алгоритма и его применения в атрибуции рекламы на телевидении публикуются в блоге нашей команды.
8 Jean-Paul [2014-03-25 13:24:00]
Найден еще один алгоритм Г. Х. Пальшикара в Простые алгоритмы для обнаружения пиков в временных рядах.
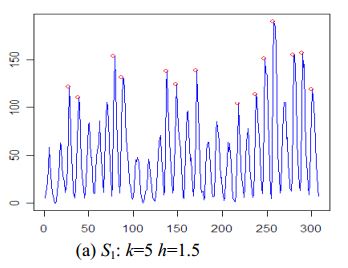
Алгоритм выглядит следующим образом:
algorithm peak1 // one peak detection algorithms that uses peak function S1
input T = x1, x2, …, xN, N // input time-series of N points
input k // window size around the peak
input h // typically 1 <= h <= 3
output O // set of peaks detected in T
begin
O = empty set // initially empty
for (i = 1; i < n; i++) do
// compute peak function value for each of the N points in T
a[i] = S1(k,i,xi,T);
end for
Compute the mean m' and standard deviation s' of all positive values in array a;
for (i = 1; i < n; i++) do // remove local peaks which are "small" in global context
if (a[i] > 0 && (a[i] – m') >( h * s')) then O = O + {xi};
end if
end for
Order peaks in O in terms of increasing index in T
// retain only one peak out of any set of peaks within distance k of each other
for every adjacent pair of peaks xi and xj in O do
if |j – i| <= k then remove the smaller value of {xi, xj} from O
end if
end for
end
Преимущества
- В документе представлены 5 различные алгоритмы обнаружения пиков
- Алгоритмы работают с необработанными данными временного ряда (не требуется сглаживание)
Недостатки
- Затрудняюсь заранее определить
kиh - Пики не могут быть плоскими (например, третий пик в моих тестовых данных)
Пример:
8 Xeoncross [2017-02-09 21:40:00]
Вот реализация алгоритма Smoothed z-score (выше) в Голанге. Он принимает кусочек []int16 (образцы 16-битных PCM). Здесь вы можете найти суть.
/*
Settings (the ones below are examples: choose what is best for your data)
set lag to 5; # lag 5 for the smoothing functions
set threshold to 3.5; # 3.5 standard deviations for signal
set influence to 0.5; # between 0 and 1, where 1 is normal influence, 0.5 is half
*/
// ZScore on 16bit WAV samples
func ZScore(samples []int16, lag int, threshold float64, influence float64) (signals []int16) {
//lag := 20
//threshold := 3.5
//influence := 0.5
signals = make([]int16, len(samples))
filteredY := make([]int16, len(samples))
for i, sample := range samples[0:lag] {
filteredY[i] = sample
}
avgFilter := make([]int16, len(samples))
stdFilter := make([]int16, len(samples))
avgFilter[lag] = Average(samples[0:lag])
stdFilter[lag] = Std(samples[0:lag])
for i := lag + 1; i < len(samples); i++ {
f := float64(samples[i])
if float64(Abs(samples[i]-avgFilter[i-1])) > threshold*float64(stdFilter[i-1]) {
if samples[i] > avgFilter[i-1] {
signals[i] = 1
} else {
signals[i] = -1
}
filteredY[i] = int16(influence*f + (1-influence)*float64(filteredY[i-1]))
avgFilter[i] = Average(filteredY[(i - lag):i])
stdFilter[i] = Std(filteredY[(i - lag):i])
} else {
signals[i] = 0
filteredY[i] = samples[i]
avgFilter[i] = Average(filteredY[(i - lag):i])
stdFilter[i] = Std(filteredY[(i - lag):i])
}
}
return
}
// Average a chunk of values
func Average(chunk []int16) (avg int16) {
var sum int64
for _, sample := range chunk {
if sample < 0 {
sample *= -1
}
sum += int64(sample)
}
return int16(sum / int64(len(chunk)))
}
6 Peter G [2014-03-31 23:43:00]
Эта проблема похожа на ту, с которой я столкнулся в гибридном/встроенном системном курсе, но это было связано с обнаружением сбоев, когда вход от датчика шумный. Мы использовали фильтр Калмана для оценки/прогнозирования скрытого состояния системы, а затем использовали статистический анализ для определения вероятности возникновения ошибки. Мы работали с линейными системами, но существуют нелинейные варианты. Я помню, что подход был удивительно адаптивным, но для этого потребовалась модель динамики системы.
6 brad [2017-10-26 17:24:00]
Вот реализация С++ сглаженного алгоритма z-score из этого ответа
std::vector<int> smoothedZScore(std::vector<float> input)
{
//lag 5 for the smoothing functions
int lag = 5;
//3.5 standard deviations for signal
float threshold = 3.5;
//between 0 and 1, where 1 is normal influence, 0.5 is half
float influence = .5;
if (input.size() <= lag + 2)
{
std::vector<int> emptyVec;
return emptyVec;
}
//Initialise variables
std::vector<int> signals(input.size(), 0.0);
std::vector<float> filteredY(input.size(), 0.0);
std::vector<float> avgFilter(input.size(), 0.0);
std::vector<float> stdFilter(input.size(), 0.0);
std::vector<float> subVecStart(input.begin(), input.begin() + lag);
avgFilter[lag] = mean(subVecStart);
stdFilter[lag] = stdDev(subVecStart);
for (size_t i = lag + 1; i < input.size(); i++)
{
if (std::abs(input[i] - avgFilter[i - 1]) > threshold * stdFilter[i - 1])
{
if (input[i] > avgFilter[i - 1])
{
signals[i] = 1; //# Positive signal
}
else
{
signals[i] = -1; //# Negative signal
}
//Make influence lower
filteredY[i] = influence* input[i] + (1 - influence) * filteredY[i - 1];
}
else
{
signals[i] = 0; //# No signal
filteredY[i] = input[i];
}
//Adjust the filters
std::vector<float> subVec(filteredY.begin() + i - lag, filteredY.begin() + i);
avgFilter[i] = mean(subVec);
stdFilter[i] = stdDev(subVec);
}
return signals;
}
4 Animesh Pandey [2017-10-29 10:55:00]
Реализация С++
#include <iostream>
#include <vector>
#include <algorithm>
#include <unordered_map>
#include <cmath>
#include <iterator>
#include <numeric>
using namespace std;
typedef long double ld;
typedef unsigned int uint;
typedef std::vector<ld>::iterator vec_iter_ld;
/**
* Overriding the ostream operator for pretty printing vectors.
*/
template<typename T>
std::ostream &operator<<(std::ostream &os, std::vector<T> vec) {
os << "[";
if (vec.size() != 0) {
std::copy(vec.begin(), vec.end() - 1, std::ostream_iterator<T>(os, " "));
os << vec.back();
}
os << "]";
return os;
}
/**
* This class calculates mean and standard deviation of a subvector.
* This is basically stats computation of a subvector of a window size qual to "lag".
*/
class VectorStats {
public:
/**
* Constructor for VectorStats class.
*
* @param start - This is the iterator position of the start of the window,
* @param end - This is the iterator position of the end of the window,
*/
VectorStats(vec_iter_ld start, vec_iter_ld end) {
this->start = start;
this->end = end;
this->compute();
}
/**
* This method calculates the mean and standard deviation using STL function.
* This is the Two-Pass implementation of the Mean & Variance calculation.
*/
void compute() {
ld sum = std::accumulate(start, end, 0.0);
uint slice_size = std::distance(start, end);
ld mean = sum / slice_size;
std::vector<ld> diff(slice_size);
std::transform(start, end, diff.begin(), [mean](ld x) { return x - mean; });
ld sq_sum = std::inner_product(diff.begin(), diff.end(), diff.begin(), 0.0);
ld std_dev = std::sqrt(sq_sum / slice_size);
this->m1 = mean;
this->m2 = std_dev;
}
ld mean() {
return m1;
}
ld standard_deviation() {
return m2;
}
private:
vec_iter_ld start;
vec_iter_ld end;
ld m1;
ld m2;
};
/**
* This is the implementation of the Smoothed Z-Score Algorithm.
* This is direction translation of https://stackoverflow.com/a/22640362/1461896.
*
* @param input - input signal
* @param lag - the lag of the moving window
* @param threshold - the z-score at which the algorithm signals
* @param influence - the influence (between 0 and 1) of new signals on the mean and standard deviation
* @return a hashmap containing the filtered signal and corresponding mean and standard deviation.
*/
unordered_map<string, vector<ld>> z_score_thresholding(vector<ld> input, int lag, ld threshold, ld influence) {
unordered_map<string, vector<ld>> output;
uint n = (uint) input.size();
vector<ld> signals(input.size());
vector<ld> filtered_input(input.begin(), input.end());
vector<ld> filtered_mean(input.size());
vector<ld> filtered_stddev(input.size());
VectorStats lag_subvector_stats(input.begin(), input.begin() + lag);
filtered_mean[lag - 1] = lag_subvector_stats.mean();
filtered_stddev[lag - 1] = lag_subvector_stats.standard_deviation();
for (int i = lag; i < n; i++) {
if (abs(input[i] - filtered_mean[i - 1]) > threshold * filtered_stddev[i - 1]) {
signals[i] = (input[i] > filtered_mean[i - 1]) ? 1.0 : -1.0;
filtered_input[i] = influence * input[i] + (1 - influence) * filtered_input[i - 1];
} else {
signals[i] = 0.0;
filtered_input[i] = input[i];
}
VectorStats lag_subvector_stats(filtered_input.begin() + (i - lag), filtered_input.begin() + i);
filtered_mean[i] = lag_subvector_stats.mean();
filtered_stddev[i] = lag_subvector_stats.standard_deviation();
}
output["signals"] = signals;
output["filtered_mean"] = filtered_mean;
output["filtered_stddev"] = filtered_stddev;
return output;
};
int main() {
vector<ld> input = {1.0, 1.0, 1.1, 1.0, 0.9, 1.0, 1.0, 1.1, 1.0, 0.9, 1.0, 1.1, 1.0, 1.0, 0.9, 1.0, 1.0, 1.1, 1.0,
1.0, 1.0, 1.0, 1.1, 0.9, 1.0, 1.1, 1.0, 1.0, 0.9, 1.0, 1.1, 1.0, 1.0, 1.1, 1.0, 0.8, 0.9, 1.0,
1.2, 0.9, 1.0, 1.0, 1.1, 1.2, 1.0, 1.5, 1.0, 3.0, 2.0, 5.0, 3.0, 2.0, 1.0, 1.0, 1.0, 0.9, 1.0,
1.0, 3.0, 2.6, 4.0, 3.0, 3.2, 2.0, 1.0, 1.0, 0.8, 4.0, 4.0, 2.0, 2.5, 1.0, 1.0, 1.0};
int lag = 30;
ld threshold = 5.0;
ld influence = 0.0;
unordered_map<string, vector<ld>> output = z_score_thresholding(input, lag, threshold, influence);
cout << output["signals"] << endl;
}
3 JoshuaCWebDeveloper [2017-10-05 01:58:00]
Вот реализация Groovy (Java) сглаженного алгоритма z-оценки (см. ответ выше).
/**
* "Smoothed zero-score alogrithm" shamelessly copied from /questions/23382/peak-signal-detection-in-realtime-timeseries-data/173212#173212
* Uses a rolling mean and a rolling deviation (separate) to identify peaks in a vector
*
* @param y - The input vector to analyze
* @param lag - The lag of the moving window (i.e. how big the window is)
* @param threshold - The z-score at which the algorithm signals (i.e. how many standard deviations away from the moving mean a peak (or signal) is)
* @param influence - The influence (between 0 and 1) of new signals on the mean and standard deviation (how much a peak (or signal) should affect other values near it)
* @return - The calculated averages (avgFilter) and deviations (stdFilter), and the signals (signals)
*/
public HashMap<String, List<Object>> thresholdingAlgo(List<Double> y, Long lag, Double threshold, Double influence) {
//init stats instance
SummaryStatistics stats = new SummaryStatistics()
//the results (peaks, 1 or -1) of our algorithm
List<Integer> signals = new ArrayList<Integer>(Collections.nCopies(y.size(), 0))
//filter out the signals (peaks) from our original list (using influence arg)
List<Double> filteredY = new ArrayList<Double>(y)
//the current average of the rolling window
List<Double> avgFilter = new ArrayList<Double>(Collections.nCopies(y.size(), 0.0d))
//the current standard deviation of the rolling window
List<Double> stdFilter = new ArrayList<Double>(Collections.nCopies(y.size(), 0.0d))
//init avgFilter and stdFilter
(0..lag-1).each { stats.addValue(y[it as int]) }
avgFilter[lag - 1 as int] = stats.getMean()
stdFilter[lag - 1 as int] = Math.sqrt(stats.getPopulationVariance()) //getStandardDeviation() uses sample variance (not what we want)
stats.clear()
//loop input starting at end of rolling window
(lag..y.size()-1).each { i ->
//if the distance between the current value and average is enough standard deviations (threshold) away
if (Math.abs((y[i as int] - avgFilter[i - 1 as int]) as Double) > threshold * stdFilter[i - 1 as int]) {
//this is a signal (i.e. peak), determine if it is a positive or negative signal
signals[i as int] = (y[i as int] > avgFilter[i - 1 as int]) ? 1 : -1
//filter this signal out using influence
filteredY[i as int] = (influence * y[i as int]) + ((1-influence) * filteredY[i - 1 as int])
} else {
//ensure this signal remains a zero
signals[i as int] = 0
//ensure this value is not filtered
filteredY[i as int] = y[i as int]
}
//update rolling average and deviation
(i - lag..i-1).each { stats.addValue(filteredY[it as int] as Double) }
avgFilter[i as int] = stats.getMean()
stdFilter[i as int] = Math.sqrt(stats.getPopulationVariance()) //getStandardDeviation() uses sample variance (not what we want)
stats.clear()
}
return [
signals : signals,
avgFilter: avgFilter,
stdFilter: stdFilter
]
}
Ниже приведен тест на том же наборе данных, который дает те же результаты, что и над реализацией Python/numpy.
// Data
def y = [1d, 1d, 1.1d, 1d, 0.9d, 1d, 1d, 1.1d, 1d, 0.9d, 1d, 1.1d, 1d, 1d, 0.9d, 1d, 1d, 1.1d, 1d, 1d,
1d, 1d, 1.1d, 0.9d, 1d, 1.1d, 1d, 1d, 0.9d, 1d, 1.1d, 1d, 1d, 1.1d, 1d, 0.8d, 0.9d, 1d, 1.2d, 0.9d, 1d,
1d, 1.1d, 1.2d, 1d, 1.5d, 1d, 3d, 2d, 5d, 3d, 2d, 1d, 1d, 1d, 0.9d, 1d,
1d, 3d, 2.6d, 4d, 3d, 3.2d, 2d, 1d, 1d, 0.8d, 4d, 4d, 2d, 2.5d, 1d, 1d, 1d]
// Settings
def lag = 30
def threshold = 5
def influence = 0
def thresholdingResults = thresholdingAlgo((List<Double>) y, (Long) lag, (Double) threshold, (Double) influence)
println y.size()
println thresholdingResults.signals.size()
println thresholdingResults.signals
thresholdingResults.signals.eachWithIndex { x, idx ->
if (x) {
println y[idx]
}
}
3 THo [2018-07-05 10:29:00]
Вот измененная версия алгоритма z-score от Fortran. Он специально изменен для обнаружения пика (резонанса) в передаточных функциях в частотном пространстве (каждое изменение имеет небольшой комментарий в коде).
Первая модификация дает предупреждение пользователю, если есть резонанс вблизи нижней границы входного вектора, обозначенный стандартным отклонением выше определенного порога (в данном случае 10%). Это просто означает, что сигнал недостаточно плоский, чтобы детектирование было правильно инициализировано фильтрами.
Вторая модификация заключается в том, что к найденным пикам добавляется только самое высокое значение пика. Это достигается путем сравнения каждого найденного пикового значения с величиной его предшественников (лаг) и его (отстающих) преемников.
Третье изменение состоит в том, чтобы учитывать, что резонансные пики обычно проявляют некоторую форму симметрии вокруг резонансной частоты. Поэтому естественно вычислять среднее и std симметрично вокруг текущей точки данных (а не только для предшественников). Это приводит к лучшему обнаружению пиков.
Модификации влияют на то, что весь сигнал должен быть известен функции заранее, что является обычным случаем для обнаружения резонанса (что-то вроде примера Matlab Jean-Paul, где точки данных генерируются "на лету", не будет работать).
function PeakDetect(y,lag,threshold, influence)
implicit none
! Declaring part
real, dimension(:), intent(in) :: y
integer, dimension(size(y)) :: PeakDetect
real, dimension(size(y)) :: filteredY, avgFilter, stdFilter
integer :: lag, ii
real :: threshold, influence
! Executing part
PeakDetect = 0
filteredY = 0.0
filteredY(1:lag+1) = y(1:lag+1)
avgFilter = 0.0
avgFilter(lag+1) = mean(y(1:2*lag+1))
stdFilter = 0.0
stdFilter(lag+1) = std(y(1:2*lag+1))
if (stdFilter(lag+1)/avgFilter(lag+1)>0.1) then ! If the coefficient of variation exceeds 10%, the signal is too uneven at the start, possibly because of a peak.
write(unit=*,fmt=1001)
1001 format(1X,'Warning: Peak detection might have failed, as there may be a peak at the edge of the frequency range.',/)
end if
do ii = lag+2, size(y)
if (abs(y(ii) - avgFilter(ii-1)) > threshold * stdFilter(ii-1)) then
! Find only the largest outstanding value which is only the one greater than its predecessor and its successor
if (y(ii) > avgFilter(ii-1) .AND. y(ii) > y(ii-1) .AND. y(ii) > y(ii+1)) then
PeakDetect(ii) = 1
end if
filteredY(ii) = influence * y(ii) + (1 - influence) * filteredY(ii-1)
else
filteredY(ii) = y(ii)
end if
! Modified with respect to the original code. Mean and standard deviation are calculted symmetrically around the current point
avgFilter(ii) = mean(filteredY(ii-lag:ii+lag))
stdFilter(ii) = std(filteredY(ii-lag:ii+lag))
end do
end function PeakDetect
real function mean(y)
!> @brief Calculates the mean of vector y
implicit none
! Declaring part
real, dimension(:), intent(in) :: y
integer :: N
! Executing part
N = max(1,size(y))
mean = sum(y)/N
end function mean
real function std(y)
!> @brief Calculates the standard deviation of vector y
implicit none
! Declaring part
real, dimension(:), intent(in) :: y
integer :: N
! Executing part
N = max(1,size(y))
std = sqrt((N*dot_product(y,y) - sum(y)**2) / (N*(N-1)))
end function std
Для моего приложения алгоритм работает как шарм! 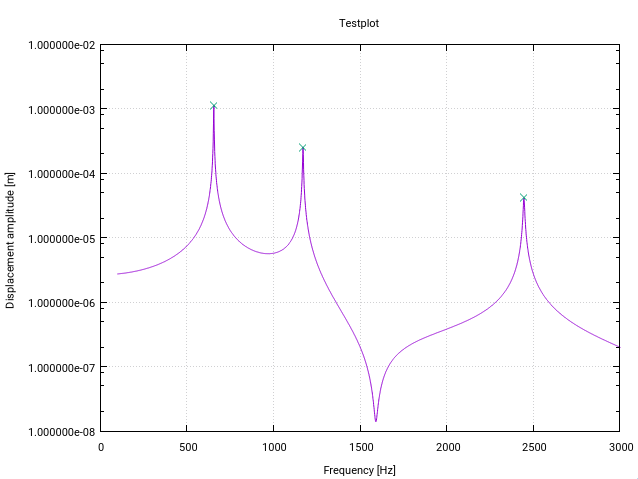
3 Mike Roberts [2018-01-12 21:13:00]
Вот (неидиоматическая) версия Scala сглаженного алгоритма z-оценки:
/**
* Smoothed zero-score alogrithm shamelessly copied from https://stackoverflow.com/a/22640362/6029703
* Uses a rolling mean and a rolling deviation (separate) to identify peaks in a vector
*
* @param y - The input vector to analyze
* @param lag - The lag of the moving window (i.e. how big the window is)
* @param threshold - The z-score at which the algorithm signals (i.e. how many standard deviations away from the moving mean a peak (or signal) is)
* @param influence - The influence (between 0 and 1) of new signals on the mean and standard deviation (how much a peak (or signal) should affect other values near it)
* @return - The calculated averages (avgFilter) and deviations (stdFilter), and the signals (signals)
*/
private def smoothedZScore(y: Seq[Double], lag: Int, threshold: Double, influence: Double): Seq[Int] = {
val stats = new SummaryStatistics()
// the results (peaks, 1 or -1) of our algorithm
val signals = mutable.ArrayBuffer.fill(y.length)(0)
// filter out the signals (peaks) from our original list (using influence arg)
val filteredY = y.to[mutable.ArrayBuffer]
// the current average of the rolling window
val avgFilter = mutable.ArrayBuffer.fill(y.length)(0d)
// the current standard deviation of the rolling window
val stdFilter = mutable.ArrayBuffer.fill(y.length)(0d)
// init avgFilter and stdFilter
y.take(lag).foreach(s => stats.addValue(s))
avgFilter(lag - 1) = stats.getMean
stdFilter(lag - 1) = Math.sqrt(stats.getPopulationVariance) // getStandardDeviation() uses sample variance (not what we want)
// loop input starting at end of rolling window
y.zipWithIndex.slice(lag, y.length - 1).foreach {
case (s: Double, i: Int) =>
// if the distance between the current value and average is enough standard deviations (threshold) away
if (Math.abs(s - avgFilter(i - 1)) > threshold * stdFilter(i - 1)) {
// this is a signal (i.e. peak), determine if it is a positive or negative signal
signals(i) = if (s > avgFilter(i - 1)) 1 else -1
// filter this signal out using influence
filteredY(i) = (influence * s) + ((1 - influence) * filteredY(i - 1))
} else {
// ensure this signal remains a zero
signals(i) = 0
// ensure this value is not filtered
filteredY(i) = s
}
// update rolling average and deviation
stats.clear()
filteredY.slice(i - lag, i).foreach(s => stats.addValue(s))
avgFilter(i) = stats.getMean
stdFilter(i) = Math.sqrt(stats.getPopulationVariance) // getStandardDeviation() uses sample variance (not what we want)
}
println(y.length)
println(signals.length)
println(signals)
signals.zipWithIndex.foreach {
case(x: Int, idx: Int) =>
if (x == 1) {
println(idx + " " + y(idx))
}
}
val data =
y.zipWithIndex.map { case (s: Double, i: Int) => Map("x" -> i, "y" -> s, "name" -> "y", "row" -> "data") } ++
avgFilter.zipWithIndex.map { case (s: Double, i: Int) => Map("x" -> i, "y" -> s, "name" -> "avgFilter", "row" -> "data") } ++
avgFilter.zipWithIndex.map { case (s: Double, i: Int) => Map("x" -> i, "y" -> (s - threshold * stdFilter(i)), "name" -> "lower", "row" -> "data") } ++
avgFilter.zipWithIndex.map { case (s: Double, i: Int) => Map("x" -> i, "y" -> (s + threshold * stdFilter(i)), "name" -> "upper", "row" -> "data") } ++
signals.zipWithIndex.map { case (s: Int, i: Int) => Map("x" -> i, "y" -> s, "name" -> "signal", "row" -> "signal") }
Vegas("Smoothed Z")
.withData(data)
.mark(Line)
.encodeX("x", Quant)
.encodeY("y", Quant)
.encodeColor(
field="name",
dataType=Nominal
)
.encodeRow("row", Ordinal)
.show
return signals
}
Здесь тест, который возвращает те же результаты, что и версии Python и Groovy:
val y = List(1d, 1d, 1.1d, 1d, 0.9d, 1d, 1d, 1.1d, 1d, 0.9d, 1d, 1.1d, 1d, 1d, 0.9d, 1d, 1d, 1.1d, 1d, 1d,
1d, 1d, 1.1d, 0.9d, 1d, 1.1d, 1d, 1d, 0.9d, 1d, 1.1d, 1d, 1d, 1.1d, 1d, 0.8d, 0.9d, 1d, 1.2d, 0.9d, 1d,
1d, 1.1d, 1.2d, 1d, 1.5d, 1d, 3d, 2d, 5d, 3d, 2d, 1d, 1d, 1d, 0.9d, 1d,
1d, 3d, 2.6d, 4d, 3d, 3.2d, 2d, 1d, 1d, 0.8d, 4d, 4d, 2d, 2.5d, 1d, 1d, 1d)
val lag = 30
val threshold = 5d
val influence = 0d
smoothedZScore(y, lag, threshold, influence)
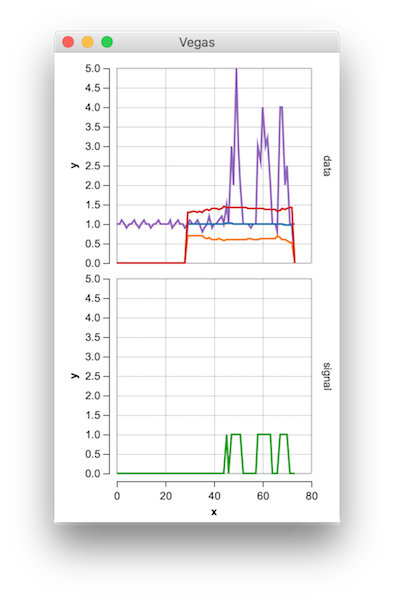
3 Tranfer Will [2018-09-09 18:40:00]
Итеративная версия в python/numpy для ответа qaru.site/questions/23382/... здесь. Этот код быстрее, чем вычисление среднего и стандартного отклонения для каждой задержки для больших данных (100000+).
def peak_detection_smoothed_zscore_v2(x, lag, threshold, influence):
'''
iterative smoothed z-score algorithm
Implementation of algorithm from /questions/23382/peak-signal-detection-in-realtime-timeseries-data/173212#173212
'''
import numpy as np
labels = np.zeros(len(x))
filtered_y = np.array(x)
avg_filter = np.zeros(len(x))
std_filter = np.zeros(len(x))
var_filter = np.zeros(len(x))
avg_filter[lag - 1] = np.mean(x[0:lag])
std_filter[lag - 1] = np.std(x[0:lag])
var_filter[lag - 1] = np.var(x[0:lag])
for i in range(lag, len(x)):
if abs(x[i] - avg_filter[i - 1]) > threshold * std_filter[i - 1]:
if x[i] > avg_filter[i - 1]:
labels[i] = 1
else:
labels[i] = -1
filtered_y[i] = influence * x[i] + (1 - influence) * filtered_y[i - 1]
else:
labels[i] = 0
filtered_y[i] = x[i]
# update avg, var, std
avg_filter[i] = avg_filter[i - 1] + 1. / lag * (filtered_y[i] - filtered_y[i - lag])
var_filter[i] = var_filter[i - 1] + 1. / lag * ((filtered_y[i] - avg_filter[i - 1]) ** 2 - (
filtered_y[i - lag] - avg_filter[i - 1]) ** 2 - (filtered_y[i] - filtered_y[i - lag]) ** 2 / lag)
std_filter[i] = np.sqrt(var_filter[i])
return dict(signals=labels,
avgFilter=avg_filter,
stdFilter=std_filter)
3 Matt Camp [2018-09-21 19:38:00]
Думал, что предоставил бы Джулию реализацию алгоритма для других. Суть можно найти здесь
using Statistics
using Plots
function SmoothedZscoreAlgo(y, lag, threshold, influence)
# Julia implimentation of http://stackoverflow.com/a/22640362/6029703
n = length(y)
signals = zeros(n) # init signal results
filteredY = copy(y) # init filtered series
avgFilter = zeros(n) # init average filter
stdFilter = zeros(n) # init std filter
avgFilter[lag - 1] = mean(y[1:lag]) # init first value
stdFilter[lag - 1] = std(y[1:lag]) # init first value
for i in range(lag, stop=n-1)
if abs(y[i] - avgFilter[i-1]) > threshold*stdFilter[i-1]
if y[i] > avgFilter[i-1]
signals[i] += 1 # postive signal
else
signals[i] += -1 # negative signal
end
# Make influence lower
filteredY[i] = influence*y[i] + (1-influence)*filteredY[i-1]
else
signals[i] = 0
filteredY[i] = y[i]
end
avgFilter[i] = mean(filteredY[i-lag+1:i])
stdFilter[i] = std(filteredY[i-lag+1:i])
end
return (signals = signals, avgFilter = avgFilter, stdFilter = stdFilter)
end
# Data
y = [1,1,1.1,1,0.9,1,1,1.1,1,0.9,1,1.1,1,1,0.9,1,1,1.1,1,1,1,1,1.1,0.9,1,1.1,1,1,0.9,
1,1.1,1,1,1.1,1,0.8,0.9,1,1.2,0.9,1,1,1.1,1.2,1,1.5,1,3,2,5,3,2,1,1,1,0.9,1,1,3,
2.6,4,3,3.2,2,1,1,0.8,4,4,2,2.5,1,1,1]
# Settings: lag = 30, threshold = 5, influence = 0
lag = 30
threshold = 5
influence = 0
results = SmoothedZscoreAlgo(y, lag, threshold, influence)
upper_bound = results[:avgFilter] + threshold * results[:stdFilter]
lower_bound = results[:avgFilter] - threshold * results[:stdFilter]
x = 1:length(y)
yplot = plot(x,y,color="blue", label="Y",legend=:topleft)
yplot = plot!(x,upper_bound, color="green", label="Upper Bound",legend=:topleft)
yplot = plot!(x,results[:avgFilter], color="cyan", label="Average Filter",legend=:topleft)
yplot = plot!(x,lower_bound, color="green", label="Lower Bound",legend=:topleft)
signalplot = plot(x,results[:signals],color="red",label="Signals",legend=:topleft)
plot(yplot,signalplot,layout=(2,1),legend=:topleft)
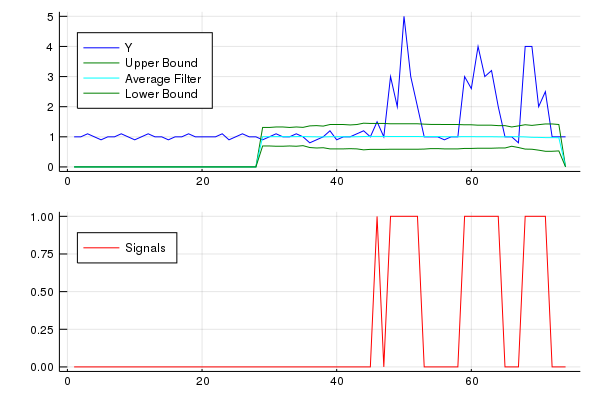
3 Ocean Airdrop [2018-12-04 16:51:00]
Следуя от предлагаемого решения от Jean-Paul, я применил его алгоритм в С#
public class ZScoreOutput
{
public List<double> input;
public List<int> signals;
public List<double> avgFilter;
public List<double> filtered_stddev;
}
public static class ZScore
{
public static ZScoreOutput StartAlgo(List<double> input, int lag, double threshold, double influence)
{
// init variables!
int[] signals = new int[input.Count];
double[] filteredY = new List<double>(input).ToArray();
double[] avgFilter = new double[input.Count];
double[] stdFilter = new double[input.Count];
var initialWindow = new List<double>(filteredY).Skip(0).Take(lag).ToList();
avgFilter[lag - 1] = Mean(initialWindow);
stdFilter[lag - 1] = StdDev(initialWindow);
for (int i = lag; i < input.Count; i++)
{
if (Math.Abs(input[i] - avgFilter[i - 1]) > threshold * stdFilter[i - 1])
{
signals[i] = (input[i] > avgFilter[i - 1]) ? 1 : -1;
filteredY[i] = influence * input[i] + (1 - influence) * filteredY[i - 1];
}
else
{
signals[i] = 0;
filteredY[i] = input[i];
}
// Update rolling average and deviation
var slidingWindow = new List<double>(filteredY).Skip(i - lag).Take(lag+1).ToList();
var tmpMean = Mean(slidingWindow);
var tmpStdDev = StdDev(slidingWindow);
avgFilter[i] = Mean(slidingWindow);
stdFilter[i] = StdDev(slidingWindow);
}
// Copy to convenience class
var result = new ZScoreOutput();
result.input = input;
result.avgFilter = new List<double>(avgFilter);
result.signals = new List<int>(signals);
result.filtered_stddev = new List<double>(stdFilter);
return result;
}
private static double Mean(List<double> list)
{
// Simple helper function!
return list.Average();
}
private static double StdDev(List<double> values)
{
double ret = 0;
if (values.Count() > 0)
{
double avg = values.Average();
double sum = values.Sum(d => Math.Pow(d - avg, 2));
ret = Math.Sqrt((sum) / (values.Count() - 1));
}
return ret;
}
}
Пример использования:
var input = new List<double> {1.0, 1.0, 1.1, 1.0, 0.9, 1.0, 1.0, 1.1, 1.0, 0.9, 1.0,
1.1, 1.0, 1.0, 0.9, 1.0, 1.0, 1.1, 1.0, 1.0, 1.0, 1.0, 1.1, 0.9, 1.0, 1.1, 1.0, 1.0, 0.9,
1.0, 1.1, 1.0, 1.0, 1.1, 1.0, 0.8, 0.9, 1.0, 1.2, 0.9, 1.0, 1.0, 1.1, 1.2, 1.0, 1.5, 1.0,
3.0, 2.0, 5.0, 3.0, 2.0, 1.0, 1.0, 1.0, 0.9, 1.0, 1.0, 3.0, 2.6, 4.0, 3.0, 3.2, 2.0, 1.0,
1.0, 0.8, 4.0, 4.0, 2.0, 2.5, 1.0, 1.0, 1.0};
int lag = 30;
double threshold = 5.0;
double influence = 0.0;
var output = ZScore.StartAlgo(input, lag, threshold, influence);
3 Kimmo Lehto [2018-02-21 02:04:00]
Вот моя попытка создать Ruby-решение для "Сглаженного z-score algo" из принятого ответа:
module ThresholdingAlgoMixin
def mean(array)
array.reduce(&:+) / array.size.to_f
end
def stddev(array)
array_mean = mean(array)
Math.sqrt(array.reduce(0.0) { |a, b| a.to_f + ((b.to_f - array_mean) ** 2) } / array.size.to_f)
end
def thresholding_algo(lag: 5, threshold: 3.5, influence: 0.5)
return nil if size < lag * 2
Array.new(size, 0).tap do |signals|
filtered = Array.new(self)
initial_slice = take(lag)
avg_filter = Array.new(lag - 1, 0.0) + [mean(initial_slice)]
std_filter = Array.new(lag - 1, 0.0) + [stddev(initial_slice)]
(lag..size-1).each do |idx|
prev = idx - 1
if (fetch(idx) - avg_filter[prev]).abs > threshold * std_filter[prev]
signals[idx] = fetch(idx) > avg_filter[prev] ? 1 : -1
filtered[idx] = (influence * fetch(idx)) + ((1-influence) * filtered[prev])
end
filtered_slice = filtered[idx-lag..prev]
avg_filter[idx] = mean(filtered_slice)
std_filter[idx] = stddev(filtered_slice)
end
end
end
end
И пример использования:
test_data = [
1, 1, 1.1, 1, 0.9, 1, 1, 1.1, 1, 0.9, 1, 1.1, 1, 1, 0.9, 1,
1, 1.1, 1, 1, 1, 1, 1.1, 0.9, 1, 1.1, 1, 1, 0.9, 1, 1.1, 1,
1, 1.1, 1, 0.8, 0.9, 1, 1.2, 0.9, 1, 1, 1.1, 1.2, 1, 1.5,
1, 3, 2, 5, 3, 2, 1, 1, 1, 0.9, 1, 1, 3, 2.6, 4, 3, 3.2, 2,
1, 1, 0.8, 4, 4, 2, 2.5, 1, 1, 1
].extend(ThresholdingAlgoMixin)
puts test_data.thresholding_algo.inspect
# Output: [
# 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
# 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, -1, 0, 0, 0,
# 0, 0, 0, 0, 0, 0, 1, 0, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 1,
# 1, 1, 0, 0, 0, -1, -1, 0, 0, 0, 0, 0, 0, 0, 0
# ]
3 leonardkraemer [2018-02-13 20:21:00]
Мне нужно что-то подобное в моем проекте Android. Я думал, что могу вернуть реализацию Котлина.
/**
* Smoothed zero-score alogrithm shamelessly copied from https://stackoverflow.com/a/22640362/6029703
* Uses a rolling mean and a rolling deviation (separate) to identify peaks in a vector
*
* @param y - The input vector to analyze
* @param lag - The lag of the moving window (i.e. how big the window is)
* @param threshold - The z-score at which the algorithm signals (i.e. how many standard deviations away from the moving mean a peak (or signal) is)
* @param influence - The influence (between 0 and 1) of new signals on the mean and standard deviation (how much a peak (or signal) should affect other values near it)
* @return - The calculated averages (avgFilter) and deviations (stdFilter), and the signals (signals)
*/
fun smoothedZScore(y: List<Double>, lag: Int, threshold: Double, influence: Double): Triple<List<Int>, List<Double>, List<Double>> {
val stats = SummaryStatistics()
// the results (peaks, 1 or -1) of our algorithm
val signals = MutableList<Int>(y.size, { 0 })
// filter out the signals (peaks) from our original list (using influence arg)
val filteredY = ArrayList<Double>(y)
// the current average of the rolling window
val avgFilter = MutableList<Double>(y.size, { 0.0 })
// the current standard deviation of the rolling window
val stdFilter = MutableList<Double>(y.size, { 0.0 })
// init avgFilter and stdFilter
y.take(lag).forEach { s -> stats.addValue(s) }
avgFilter[lag - 1] = stats.mean
stdFilter[lag - 1] = Math.sqrt(stats.populationVariance) // getStandardDeviation() uses sample variance (not what we want)
stats.clear()
//loop input starting at end of rolling window
(lag..y.size - 1).forEach { i ->
//if the distance between the current value and average is enough standard deviations (threshold) away
if (Math.abs(y[i] - avgFilter[i - 1]) > threshold * stdFilter[i - 1]) {
//this is a signal (i.e. peak), determine if it is a positive or negative signal
signals[i] = if (y[i] > avgFilter[i - 1]) 1 else -1
//filter this signal out using influence
filteredY[i] = (influence * y[i]) + ((1 - influence) * filteredY[i - 1])
} else {
//ensure this signal remains a zero
signals[i] = 0
//ensure this value is not filtered
filteredY[i] = y[i]
}
//update rolling average and deviation
(i - lag..i - 1).forEach { stats.addValue(filteredY[it]) }
avgFilter[i] = stats.getMean()
stdFilter[i] = Math.sqrt(stats.getPopulationVariance()) //getStandardDeviation() uses sample variance (not what we want)
stats.clear()
}
return Triple(signals, avgFilter, stdFilter)
}
Пример проекта с графами проверки можно найти в github.
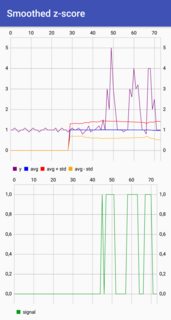
2 hotpaw2 [2014-03-24 04:57:00]
Если граничное значение или другие критерии зависят от будущих значений, то единственным решением (без машины времени или другим знанием будущих значений) является отсрочка любого решения до тех пор, пока у вас не будет достаточно будущих значений. Если вы хотите, чтобы уровень выше среднего, который охватывает, например, 20 очков, тогда вам нужно подождать, пока у вас не будет на 19 очков раньше любого пикового решения, иначе следующий новый пункт может полностью сбросить ваш порог 19 очков назад.
В вашем текущем сюжете нет пиков... если вы как-то заранее не узнаете, что самая следующая точка - это не 1e99, которая после изменения размера вашего графика Y будет плоской до этой точки.
1 nichole [2017-03-13 07:23:00]
Вместо сравнения максимумов со средним можно сравнить максимумы с соседними минимумами, где минимумы определяются только над порогом шума. Если локальный максимум равен > 3 раза (или другому доверительному коэффициенту) или соседним минимумам, то максимальные значения являются пиком. Определение пика более точно с более широкими движущимися окнами. В приведенном выше примере вычисляется центрированное по середине окна, кстати, а не вычисление в конце окна (== lag).
Обратите внимание, что максимум следует рассматривать как увеличение сигнала до и уменьшение после.
1 Ocean Airdrop [2018-12-03 16:27:00]
Если у вас есть данные в таблице базы данных, вот SQL-версия простого алгоритма z-score:
with data_with_zscore as (
select
date_time,
value,
value / (avg(value) over ()) as pct_of_mean,
(value - avg(value) over ()) / (stdev(value) over ()) as z_score
from {{tablename}} where datetime > '2018-11-26' and datetime < '2018-12-03'
)
-- select all
select * from data_with_zscore
-- select only points greater than a certain threshold
select * from data_with_zscore where z_score > abs(2)
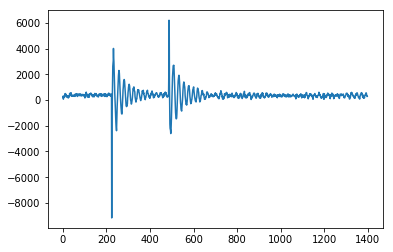
1 DavidC [2019-02-03 23:16:00]
Здесь реализация C сглаженного Z-показателя @Jean-Paul для микроконтроллера Arduino, используемая для считывания показаний акселерометра и определения того, произошло ли направление удара слева направо. Это работает очень хорошо, так как это устройство возвращает отклоненный сигнал. Вот этот вход для этого алгоритма обнаружения пика от устройства - показывает удар справа, а затем удар слева. Вы можете увидеть начальный всплеск, а затем колебание датчика.
#include <stdio.h>
#include <math.h>
#include <string.h>
#define SAMPLE_LENGTH 1000
float stddev(float data[], int len);
float mean(float data[], int len);
void thresholding(float y[], int signals[], int lag, float threshold, float influence);
void thresholding(float y[], int signals[], int lag, float threshold, float influence) {
memset(signals, 0, sizeof(float) * SAMPLE_LENGTH);
float filteredY[SAMPLE_LENGTH];
memcpy(filteredY, y, sizeof(float) * SAMPLE_LENGTH);
float avgFilter[SAMPLE_LENGTH];
float stdFilter[SAMPLE_LENGTH];
avgFilter[lag - 1] = mean(y, lag);
stdFilter[lag - 1] = stddev(y, lag);
for (int i = lag; i < SAMPLE_LENGTH; i++) {
if (fabsf(y[i] - avgFilter[i-1]) > threshold * stdFilter[i-1]) {
if (y[i] > avgFilter[i-1]) {
signals[i] = 1;
} else {
signals[i] = -1;
}
filteredY[i] = influence * y[i] + (1 - influence) * filteredY[i-1];
} else {
signals[i] = 0;
}
avgFilter[i] = mean(filteredY + i-lag, lag);
stdFilter[i] = stddev(filteredY + i-lag, lag);
}
}
float mean(float data[], int len) {
float sum = 0.0, mean = 0.0;
int i;
for(i=0; i<len; ++i) {
sum += data[i];
}
mean = sum/len;
return mean;
}
float stddev(float data[], int len) {
float the_mean = mean(data, len);
float standardDeviation = 0.0;
int i;
for(i=0; i<len; ++i) {
standardDeviation += pow(data[i] - the_mean, 2);
}
return sqrt(standardDeviation/len);
}
int main() {
printf("Hello, World!\n");
int lag = 100;
float threshold = 5;
float influence = 0;
float y[]= {1,1,1.1,1,0.9,1,1,1.1,1,0.9,1,1.1,1,1,0.9,1,1,1.1,1,1,1,1,1.1,0.9,1,1.1,1,1,0.9,
....
1,1.1,1,1,1.1,1,0.8,0.9,1,1.2,0.9,1,1,1.1,1.2,1,1.5,1,3,2,5,3,2,1,1,1,0.9,1,1,3, 2.6,4,3,3.2,2,1,1,0.8,4,4,2,2.5,1,1,1,1.2,1,1.5,1,3,2,5,3,2,1,1,1,0.9,1,1,3,
2.6,4,3,3.2,2,1,1,0.8,4,4,2,2.5,1,1,1}
int signal[SAMPLE_LENGTH];
thresholding(y, signal, lag, threshold, influence);
return 0;
}
Ее результат с влиянием = 0
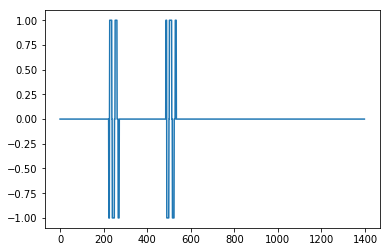
Не отлично, но здесь с влиянием = 1
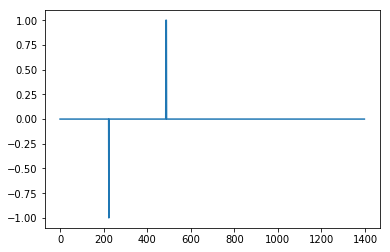
что очень хорошо
0 Jean-Paul [2019-02-03 23:37:00]
Приложение 1 к первоначальному ответу: переводы Matlab и R
Код Matlab
function [signals,avgFilter,stdFilter] = ThresholdingAlgo(y,lag,threshold,influence)
% Initialise signal results
signals = zeros(length(y),1);
% Initialise filtered series
filteredY = y(1:lag+1);
% Initialise filters
avgFilter(lag+1,1) = mean(y(1:lag+1));
stdFilter(lag+1,1) = std(y(1:lag+1));
% Loop over all datapoints y(lag+2),...,y(t)
for i=lag+2:length(y)
% If new value is a specified number of deviations away
if abs(y(i)-avgFilter(i-1)) > threshold*stdFilter(i-1)
if y(i) > avgFilter(i-1)
% Positive signal
signals(i) = 1;
else
% Negative signal
signals(i) = -1;
end
% Make influence lower
filteredY(i) = influence*y(i)+(1-influence)*filteredY(i-1);
else
% No signal
signals(i) = 0;
filteredY(i) = y(i);
end
% Adjust the filters
avgFilter(i) = mean(filteredY(i-lag:i));
stdFilter(i) = std(filteredY(i-lag:i));
end
% Done, now return results
end
Пример:
% Data
y = [1 1 1.1 1 0.9 1 1 1.1 1 0.9 1 1.1 1 1 0.9 1 1 1.1 1 1,...
1 1 1.1 0.9 1 1.1 1 1 0.9 1 1.1 1 1 1.1 1 0.8 0.9 1 1.2 0.9 1,...
1 1.1 1.2 1 1.5 1 3 2 5 3 2 1 1 1 0.9 1,...
1 3 2.6 4 3 3.2 2 1 1 0.8 4 4 2 2.5 1 1 1];
% Settings
lag = 30;
threshold = 5;
influence = 0;
% Get results
[signals,avg,dev] = ThresholdingAlgo(y,lag,threshold,influence);
figure; subplot(2,1,1); hold on;
x = 1:length(y); ix = lag+1:length(y);
area(x(ix),avg(ix)+threshold*dev(ix),'FaceColor',[0.9 0.9 0.9],'EdgeColor','none');
area(x(ix),avg(ix)-threshold*dev(ix),'FaceColor',[1 1 1],'EdgeColor','none');
plot(x(ix),avg(ix),'LineWidth',1,'Color','cyan','LineWidth',1.5);
plot(x(ix),avg(ix)+threshold*dev(ix),'LineWidth',1,'Color','green','LineWidth',1.5);
plot(x(ix),avg(ix)-threshold*dev(ix),'LineWidth',1,'Color','green','LineWidth',1.5);
plot(1:length(y),y,'b');
subplot(2,1,2);
stairs(signals,'r','LineWidth',1.5); ylim([-1.5 1.5]);
Код R
ThresholdingAlgo <- function(y,lag,threshold,influence) {
signals <- rep(0,length(y))
filteredY <- y[0:lag]
avgFilter <- NULL
stdFilter <- NULL
avgFilter[lag] <- mean(y[0:lag])
stdFilter[lag] <- sd(y[0:lag])
for (i in (lag+1):length(y)){
if (abs(y[i]-avgFilter[i-1]) > threshold*stdFilter[i-1]) {
if (y[i] > avgFilter[i-1]) {
signals[i] <- 1;
} else {
signals[i] <- -1;
}
filteredY[i] <- influence*y[i]+(1-influence)*filteredY[i-1]
} else {
signals[i] <- 0
filteredY[i] <- y[i]
}
avgFilter[i] <- mean(filteredY[(i-lag):i])
stdFilter[i] <- sd(filteredY[(i-lag):i])
}
return(list("signals"=signals,"avgFilter"=avgFilter,"stdFilter"=stdFilter))
}
Пример:
# Data
y <- c(1,1,1.1,1,0.9,1,1,1.1,1,0.9,1,1.1,1,1,0.9,1,1,1.1,1,1,1,1,1.1,0.9,1,1.1,1,1,0.9,
1,1.1,1,1,1.1,1,0.8,0.9,1,1.2,0.9,1,1,1.1,1.2,1,1.5,1,3,2,5,3,2,1,1,1,0.9,1,1,3,
2.6,4,3,3.2,2,1,1,0.8,4,4,2,2.5,1,1,1)
lag <- 30
threshold <- 5
influence <- 0
# Run algo with lag = 30, threshold = 5, influence = 0
result <- ThresholdingAlgo(y,lag,threshold,influence)
# Plot result
par(mfrow = c(2,1),oma = c(2,2,0,0) + 0.1,mar = c(0,0,2,1) + 0.2)
plot(1:length(y),y,type="l",ylab="",xlab="")
lines(1:length(y),result$avgFilter,type="l",col="cyan",lwd=2)
lines(1:length(y),result$avgFilter+threshold*result$stdFilter,type="l",col="green",lwd=2)
lines(1:length(y),result$avgFilter-threshold*result$stdFilter,type="l",col="green",lwd=2)
plot(result$signals,type="S",col="red",ylab="",xlab="",ylim=c(-1.5,1.5),lwd=2)
Этот код (оба языка) даст следующий результат для данных исходного вопроса:
Приложение 2 к первоначальному ответу: демонстрационный код Matlab
(нажмите, чтобы создать данные)
function [] = RobustThresholdingDemo()
%% SPECIFICATIONS
lag = 5; % lag for the smoothing
threshold = 3.5; % number of st.dev. away from the mean to signal
influence = 0.3; % when signal: how much influence for new data? (between 0 and 1)
% 1 is normal influence, 0.5 is half
%% START DEMO
DemoScreen(30,lag,threshold,influence);
end
function [signals,avgFilter,stdFilter] = ThresholdingAlgo(y,lag,threshold,influence)
signals = zeros(length(y),1);
filteredY = y(1:lag+1);
avgFilter(lag+1,1) = mean(y(1:lag+1));
stdFilter(lag+1,1) = std(y(1:lag+1));
for i=lag+2:length(y)
if abs(y(i)-avgFilter(i-1)) > threshold*stdFilter(i-1)
if y(i) > avgFilter(i-1)
signals(i) = 1;
else
signals(i) = -1;
end
filteredY(i) = influence*y(i)+(1-influence)*filteredY(i-1);
else
signals(i) = 0;
filteredY(i) = y(i);
end
avgFilter(i) = mean(filteredY(i-lag:i));
stdFilter(i) = std(filteredY(i-lag:i));
end
end
% Demo screen function
function [] = DemoScreen(n,lag,threshold,influence)
figure('Position',[200 100,1000,500]);
subplot(2,1,1);
title(sprintf(['Draw data points (%.0f max) [settings: lag = %.0f, '...
'threshold = %.2f, influence = %.2f]'],n,lag,threshold,influence));
ylim([0 5]); xlim([0 50]);
H = gca; subplot(2,1,1);
set(H, 'YLimMode', 'manual'); set(H, 'XLimMode', 'manual');
set(H, 'YLim', get(H,'YLim')); set(H, 'XLim', get(H,'XLim'));
xg = []; yg = [];
for i=1:n
try
[xi,yi] = ginput(1);
catch
return;
end
xg = [xg xi]; yg = [yg yi];
if i == 1
subplot(2,1,1); hold on;
plot(H, xg(i),yg(i),'r.');
text(xg(i),yg(i),num2str(i),'FontSize',7);
end
if length(xg) > lag
[signals,avg,dev] = ...
ThresholdingAlgo(yg,lag,threshold,influence);
area(xg(lag+1:end),avg(lag+1:end)+threshold*dev(lag+1:end),...
'FaceColor',[0.9 0.9 0.9],'EdgeColor','none');
area(xg(lag+1:end),avg(lag+1:end)-threshold*dev(lag+1:end),...
'FaceColor',[1 1 1],'EdgeColor','none');
plot(xg(lag+1:end),avg(lag+1:end),'LineWidth',1,'Color','cyan');
plot(xg(lag+1:end),avg(lag+1:end)+threshold*dev(lag+1:end),...
'LineWidth',1,'Color','green');
plot(xg(lag+1:end),avg(lag+1:end)-threshold*dev(lag+1:end),...
'LineWidth',1,'Color','green');
subplot(2,1,2); hold on; title('Signal output');
stairs(xg(lag+1:end),signals(lag+1:end),'LineWidth',2,'Color','blue');
ylim([-2 2]); xlim([0 50]); hold off;
end
subplot(2,1,1); hold on;
for j=2:i
plot(xg([j-1:j]),yg([j-1:j]),'r'); plot(H,xg(j),yg(j),'r.');
text(xg(j),yg(j),num2str(j),'FontSize',7);
end
end
end
0 mrk [2019-01-09 03:50:00]
Функция scipy.signal.find_peaks, как следует из ее названия, полезна для этого. Но важно хорошо понимать его параметры width, threshold, distance и, прежде всего, prominence чтобы получить хороший пик извлечения.
Согласно моим тестам и документации, концепция значимости является "полезной концепцией" для сохранения хороших пиков и устранения шумовых пиков.
Что такое (топографическая) известность? Это "минимальная высота, необходимая для спуска, чтобы добраться от вершины к любой более высокой местности", как это можно увидеть здесь:
Идея заключается в следующем:
Чем выше известность, тем "важнее" пик.